[1]:
import os, random, argparse, pandas as pd, numpy as np, seaborn as sns
from tqdm import tqdm
import torch, torch.nn as nn
# set random seed
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
SEED = 10
random.seed(SEED)
np.random.seed(SEED)
torch.random.manual_seed(SEED)
# load package requirments
from DeepRUOT.losses import MMD_loss, OT_loss1, OT_loss2, Density_loss, Local_density_loss
from DeepRUOT.utils import group_extract, sample, to_np, generate_steps, cal_mass_loss, parser, _valid_criterions
from DeepRUOT.plots import plot_comparision, plot_losses
from DeepRUOT.train import train_un1
from DeepRUOT.models import velocityNet, growthNet, scoreNet, dediffusionNet, indediffusionNet, FNet, ODEFunc2
from DeepRUOT.constants import ROOT_DIR, DATA_DIR, NTBK_DIR, IMGS_DIR, RES_DIR
from DeepRUOT.exp import setup_exp
from DeepRUOT.eval import generate_plot_data
from torchdiffeq import odeint_adjoint as odeint
#from torchdiffeq import odeint
# for geodesic learning
from scipy.spatial import distance_matrix
from sklearn.gaussian_process.kernels import RBF
from sklearn.manifold import MDS
[2]:
import torch.optim as optim
dim=10
f_net = FNet(in_out_dim=dim, hidden_dim=128, n_hiddens=3, activation='leakyrelu')
import sys
# Simulate the command-line arguments
sys.argv = [
'DeepRUOT Training',
'-d', 'file',
'-c', 'ot1',
'-n', 'emt',
]
args = parser.parse_args()
opts = vars(args)
# Display the parsed arguments
print(opts)
device = torch.device('cuda')
device
{'dataset': 'file', 'time_col': None, 'name': 'emt', 'output_dir': '/lustre/home/2301110060/DeepRUOT/results', 'local_epochs': 5, 'epochs': 15, 'local_post_epochs': 5, 'criterion': 'ot1', 'batches': 100, 'cuda': True, 'sample_size': 100, 'sample_with_replacement': False, 'hold_one_out': True, 'hold_out': 'random', 'apply_losses_in_time': True, 'top_k': 5, 'hinge_value': 0.01, 'use_density_loss': True, 'use_local_density': False, 'lambda_density': 1.0, 'lambda_density_local': 1.0, 'lambda_local': 0.2, 'lambda_global': 0.8, 'model_layers': [64], 'use_geo': False, 'geo_layers': [32], 'geo_features': 5, 'n_points': 100, 'n_trajectories': 30, 'n_bins': 100}
[2]:
device(type='cuda')
[3]:
df=pd.read_csv(DATA_DIR + '/emt.csv')
# make output dir
if not os.path.isdir(opts['output_dir']):
os.makedirs(opts['output_dir'])
exp_dir, logger = setup_exp(opts['output_dir'], opts, opts['name'])
# load dataset
logger.info(f'Loading dataset')
[4]:
# setup groups
groups = sorted(df.samples.unique())
steps = generate_steps(groups)
logger.info(f'Defining model')
use_geo = opts['use_geo']
model_layers = opts['model_layers']
model_features = len(df.columns) - 1
logger.info(f'Defining optimizer and criterion')
optimizer = torch.optim.Adam(f_net.parameters())
opts['criterion']='ot1'
criterion = _valid_criterions[opts['criterion']]()
logger.info(f'Extracting parameters')
use_cuda = torch.cuda.is_available() and opts['cuda']
sample_size = (opts['sample_size'], )
sample_with_replacement = opts['sample_with_replacement' ]
apply_losses_in_time = opts['apply_losses_in_time']
n_local_epochs = opts['local_epochs']
n_epochs = opts['epochs']
n_post_local_epochs = opts['local_post_epochs']
n_batches = opts['batches']
hold_one_out = opts['hold_one_out']
hold_out = opts['hold_out']
hinge_value = opts['hinge_value']
top_k = opts['top_k']
lambda_density = opts['lambda_density']
lambda_density_local = opts['lambda_density_local']
use_density_loss = opts['use_density_loss']
use_local_density = opts['use_local_density']
lambda_local = opts['lambda_local']
lambda_global = opts['lambda_global']
n_points=opts['n_points']
n_trajectories=opts['n_trajectories']
n_bins=opts['n_bins']
local_losses = {f'{t0}:{t1}':[] for (t0, t1) in steps}
batch_losses = []
globe_losses = []
[5]:
f_net=f_net.to(device)
f_net
[5]:
FNet(
(v_net): velocityNet(
(activation): LeakyReLU(negative_slope=0.01)
(net): ModuleList(
(0): Sequential(
(0): Linear(in_features=11, out_features=128, bias=True)
(1): LeakyReLU(negative_slope=0.01)
)
(1-2): 2 x Sequential(
(0): Linear(in_features=128, out_features=128, bias=True)
(1): LeakyReLU(negative_slope=0.01)
)
)
(out): Linear(in_features=128, out_features=10, bias=True)
)
(g_net): growthNet(
(activation): LeakyReLU(negative_slope=0.01)
(net): Sequential(
(0): Linear(in_features=11, out_features=128, bias=True)
(1): LeakyReLU(negative_slope=0.01)
(2): Linear(in_features=128, out_features=128, bias=True)
(3): LeakyReLU(negative_slope=0.01)
(4): Linear(in_features=128, out_features=128, bias=True)
(5): LeakyReLU(negative_slope=0.01)
(6): Linear(in_features=128, out_features=1, bias=True)
)
)
(s_net): scoreNet(
(activation): LeakyReLU(negative_slope=0.01)
(net): Sequential(
(0): Linear(in_features=11, out_features=128, bias=True)
(1): LeakyReLU(negative_slope=0.01)
(2): Linear(in_features=128, out_features=128, bias=True)
(3): LeakyReLU(negative_slope=0.01)
(4): Linear(in_features=128, out_features=128, bias=True)
(5): LeakyReLU(negative_slope=0.01)
(6): Linear(in_features=128, out_features=1, bias=True)
)
)
(d_net): indediffusionNet(
(activation): LeakyReLU(negative_slope=0.01)
(net): Sequential(
(0): Linear(in_features=1, out_features=128, bias=True)
(1): LeakyReLU(negative_slope=0.01)
(2): Linear(in_features=128, out_features=128, bias=True)
(3): LeakyReLU(negative_slope=0.01)
(4): Linear(in_features=128, out_features=128, bias=True)
(5): LeakyReLU(negative_slope=0.01)
(6): Linear(in_features=128, out_features=1, bias=True)
)
)
)
[6]:
initial_size=df[df['samples']==0].x1.shape[0]
initial_size
[6]:
577
[7]:
sample_sizes = df.groupby('samples').size()
ref0 = sample_sizes / sample_sizes.iloc[0]
relative_mass = torch.tensor(ref0.values)
relative_mass
[7]:
tensor([1.0000, 1.5338, 1.3657, 1.5303], dtype=torch.float64)
[8]:
sample_size = (df[df['samples']==0.0].values.shape[0],)
PreTrain velocity and growth
[9]:
if n_local_epochs > 0:
logger.info(f'Beginning pretraining')
for epoch in tqdm(range(1), desc='Pretraining Epoch'):
l_loss, b_loss, g_loss = train_un1(
f_net, df, groups, optimizer,30,
criterion = criterion, use_cuda = use_cuda,
local_loss=True, global_loss=False, apply_losses_in_time=apply_losses_in_time,
hold_one_out=hold_one_out, hold_out=hold_out,
hinge_value=hinge_value, lambda_ot=0.1, lambda_mass=1, lambda_energy=0.001,
use_pinn=False, use_penalty=False,use_density_loss=False,lambda_density=10,
top_k = top_k, sample_size = sample_size,relative_mass=relative_mass,initial_size=initial_size,
sample_with_replacement = sample_with_replacement, logger=logger, device=device,best_model_path=exp_dir+'/best_model'
)
for k, v in l_loss.items():
local_losses[k].extend(v)
batch_losses.extend(b_loss)
globe_losses.extend(g_loss)
Pretraining Epoch: 0%| | 0/1 [00:00<?, ?it/s]
begin local loss
Otloss
tensor(0.1700, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0193, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.3781, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0798, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.6073, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.5121, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.6072728633880615. Model saved.
Otloss
tensor(0.1137, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0103, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1791, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0220, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.2457, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0462, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.2457018494606018. Model saved.
Otloss
tensor(0.0945, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0075, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1120, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0085, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1666, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0187, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.16664665937423706. Model saved.
Otloss
tensor(0.0936, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0078, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1187, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0084, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.2180, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0236, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0930, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0075, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1173, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0091, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1955, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0210, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0862, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0066, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1011, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0075, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1500, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0151, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.14996205270290375. Model saved.
Otloss
tensor(0.0804, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0057, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0945, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0075, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1376, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0153, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.13762015104293823. Model saved.
Otloss
tensor(0.0775, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0050, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0960, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0090, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1346, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0146, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.1345514953136444. Model saved.
Otloss
tensor(0.0760, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0045, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0976, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0087, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1217, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0128, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.12168321758508682. Model saved.
Otloss
tensor(0.0742, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0045, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0977, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0076, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1055, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0095, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.10546368360519409. Model saved.
Otloss
tensor(0.0718, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0045, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0970, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0070, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0953, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0074, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.09534205496311188. Model saved.
Otloss
tensor(0.0698, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0040, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0946, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0066, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0920, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0063, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.09199593216180801. Model saved.
Otloss
tensor(0.0696, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0042, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0920, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0071, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0946, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0069, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0703, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0043, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0886, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0065, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0975, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0076, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0699, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0043, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0844, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0060, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0961, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0074, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0694, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0042, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0837, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0056, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0940, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0069, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0690, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0040, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0852, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0054, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0904, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0066, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.09037873893976212. Model saved.
Otloss
tensor(0.0682, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0040, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0854, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0058, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0855, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0061, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.08546467125415802. Model saved.
Otloss
tensor(0.0677, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0040, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0848, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0059, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0834, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0062, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.0834236741065979. Model saved.
Otloss
tensor(0.0675, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0038, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0836, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0056, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0833, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0059, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.08330996334552765. Model saved.
Otloss
tensor(0.0673, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0038, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0813, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0049, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0823, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0058, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.0823383778333664. Model saved.
Otloss
tensor(0.0671, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0039, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0792, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0047, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0826, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0057, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0669, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0039, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0780, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0045, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0829, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0055, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0665, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0038, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0769, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0044, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0805, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0053, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.08051622658967972. Model saved.
Otloss
tensor(0.0660, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0038, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0768, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0045, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0800, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0051, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.07996969670057297. Model saved.
Otloss
tensor(0.0655, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0037, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0766, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0046, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0785, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0049, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.07851728796958923. Model saved.
Otloss
tensor(0.0652, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0038, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0754, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0043, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0782, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0052, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.0781906396150589. Model saved.
Otloss
tensor(0.0650, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0038, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0734, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0037, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0790, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0051, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0648, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0037, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0722, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0039, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0777, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0044, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.07765759527683258. Model saved.
Otloss
tensor(0.0645, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0038, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0723, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0039, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0776, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0045, device='cuda:0', grad_fn=<PowBackward0>)
Pretraining Epoch: 100%|██████████| 1/1 [00:56<00:00, 56.98s/it]
New minimum otloss found: 0.07756981253623962. Model saved.
[10]:
f_net.load_state_dict(torch.load(os.path.join(exp_dir+'/best_model'),map_location=torch.device('cpu')))
f_net.to(device)
for param in f_net.g_net.parameters():
param.requires_grad = False
[11]:
if n_local_epochs > 0:
logger.info(f'Beginning pretraining')
for epoch in tqdm(range(1), desc='Pretraining Epoch'):
l_loss, b_loss, g_loss = train_un1(
f_net, df, groups, optimizer,10,
criterion = criterion, use_cuda = use_cuda,
local_loss=True, global_loss=False, apply_losses_in_time=apply_losses_in_time,
hold_one_out=hold_one_out, hold_out=hold_out,
hinge_value=hinge_value, lambda_ot=0.1, lambda_mass=0, lambda_energy=0.001,
use_pinn=False, use_penalty=False,use_density_loss=False,lambda_density=10,
top_k = top_k, sample_size = sample_size,relative_mass=relative_mass,initial_size=initial_size,
sample_with_replacement = sample_with_replacement, logger=logger, device=device,best_model_path=exp_dir+'/best_model'
)
for k, v in l_loss.items():
local_losses[k].extend(v)
batch_losses.extend(b_loss)
globe_losses.extend(g_loss)
Pretraining Epoch: 0%| | 0/1 [00:00<?, ?it/s]
begin local loss
Otloss
tensor(0.0642, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0038, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0713, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0035, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0780, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0048, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.07804079353809357. Model saved.
Otloss
tensor(0.0640, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0037, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0708, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0035, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0761, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0048, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.07610562443733215. Model saved.
Otloss
tensor(0.0639, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0037, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0715, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0039, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0775, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0047, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0636, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0037, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0697, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0031, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0764, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0045, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0638, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0037, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0701, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0033, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0768, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0046, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0634, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0036, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0693, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0033, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0773, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0044, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0635, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0037, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0688, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0033, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0761, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0047, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.07606751471757889. Model saved.
Otloss
tensor(0.0631, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0036, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0692, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0031, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0779, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0048, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0632, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0035, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0695, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0032, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0754, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0047, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.07541188597679138. Model saved.
Otloss
tensor(0.0631, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0036, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0685, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0032, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0764, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0044, device='cuda:0', grad_fn=<PowBackward0>)
Pretraining Epoch: 100%|██████████| 1/1 [00:17<00:00, 17.16s/it]
[12]:
f_net.load_state_dict(torch.load(os.path.join(exp_dir+'/best_model'),map_location=torch.device('cpu')))
f_net.to(device)
[12]:
FNet(
(v_net): velocityNet(
(activation): LeakyReLU(negative_slope=0.01)
(net): ModuleList(
(0): Sequential(
(0): Linear(in_features=11, out_features=128, bias=True)
(1): LeakyReLU(negative_slope=0.01)
)
(1-2): 2 x Sequential(
(0): Linear(in_features=128, out_features=128, bias=True)
(1): LeakyReLU(negative_slope=0.01)
)
)
(out): Linear(in_features=128, out_features=10, bias=True)
)
(g_net): growthNet(
(activation): LeakyReLU(negative_slope=0.01)
(net): Sequential(
(0): Linear(in_features=11, out_features=128, bias=True)
(1): LeakyReLU(negative_slope=0.01)
(2): Linear(in_features=128, out_features=128, bias=True)
(3): LeakyReLU(negative_slope=0.01)
(4): Linear(in_features=128, out_features=128, bias=True)
(5): LeakyReLU(negative_slope=0.01)
(6): Linear(in_features=128, out_features=1, bias=True)
)
)
(s_net): scoreNet(
(activation): LeakyReLU(negative_slope=0.01)
(net): Sequential(
(0): Linear(in_features=11, out_features=128, bias=True)
(1): LeakyReLU(negative_slope=0.01)
(2): Linear(in_features=128, out_features=128, bias=True)
(3): LeakyReLU(negative_slope=0.01)
(4): Linear(in_features=128, out_features=128, bias=True)
(5): LeakyReLU(negative_slope=0.01)
(6): Linear(in_features=128, out_features=1, bias=True)
)
)
(d_net): indediffusionNet(
(activation): LeakyReLU(negative_slope=0.01)
(net): Sequential(
(0): Linear(in_features=1, out_features=128, bias=True)
(1): LeakyReLU(negative_slope=0.01)
(2): Linear(in_features=128, out_features=128, bias=True)
(3): LeakyReLU(negative_slope=0.01)
(4): Linear(in_features=128, out_features=128, bias=True)
(5): LeakyReLU(negative_slope=0.01)
(6): Linear(in_features=128, out_features=1, bias=True)
)
)
)
[13]:
import torch
import matplotlib.pyplot as plt
import numpy as np
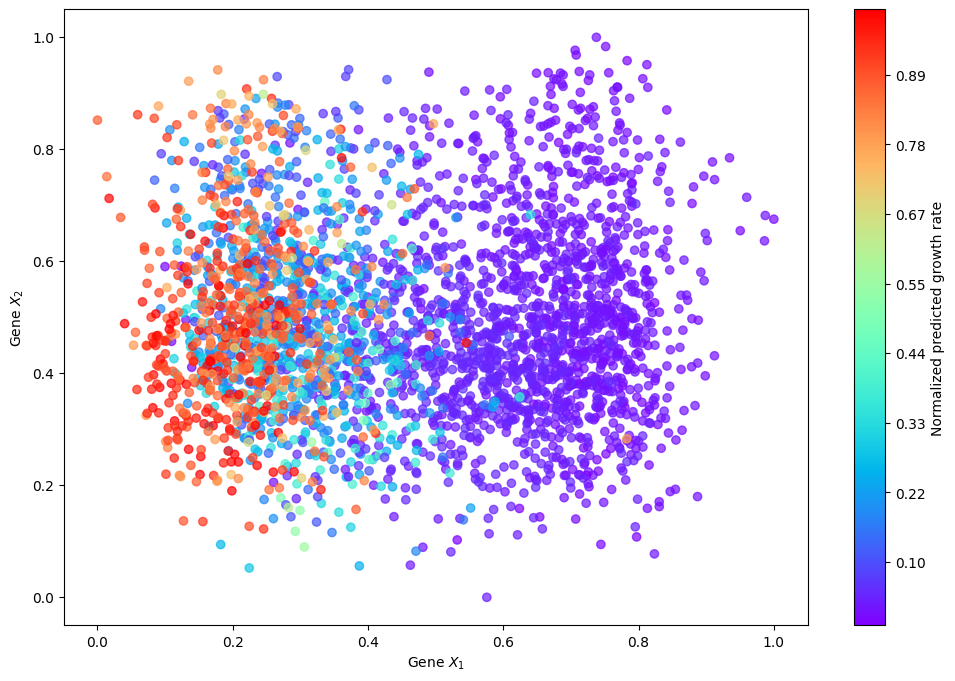
def plot_g_values(df, f_net, device=device, output_file='plot.pdf'):
time_points = df['samples'].unique()
data_by_time = {}
for time in time_points:
subset = df[df['samples'] == time]
n = 10
column_names = [f'x{i}' for i in range(1, n + 1)]
tensors = [torch.tensor(subset[col].values, dtype=torch.float32).to(device) for col in column_names]
data = torch.stack(tensors, dim=1)
with torch.no_grad():
t = torch.tensor([time], dtype=torch.float32).to(device)
_, g, _, _ = f_net(t, data)
data_by_time[time] = {'data': subset, 'g_values': g.detach().cpu().numpy()}
all_g_values = np.concatenate([content['g_values'] for content in data_by_time.values()])
vmax_value = np.percentile(all_g_values, 99)
norm = plt.Normalize(vmin=all_g_values.min(), vmax=vmax_value, clip=True)
fig, ax = plt.subplots(figsize=(12, 8))
for time, content in data_by_time.items():
subset = content['data']
g_values = content['g_values']
x = subset['x1']
y = subset['x2']
colors = plt.cm.rainbow(norm(g_values))
ax.scatter(x, y, color=colors, label=f'Time {time}', alpha=0.7, marker='o')
ax.set_xlabel('Gene $X_1$')
ax.set_ylabel('Gene $X_2$')
sm = plt.cm.ScalarMappable(cmap='rainbow', norm=norm)
sm.set_array(all_g_values)
cbar = fig.colorbar(sm, ax=ax)
cbar.set_label('Normalized predicted growth rate')
cbar.ax.yaxis.set_major_formatter(plt.FuncFormatter(lambda x, _: f'{norm(x):.2f}'))
plt.show()
plot_g_values(df, f_net, output_file='gene_growth_pre_post.pdf')
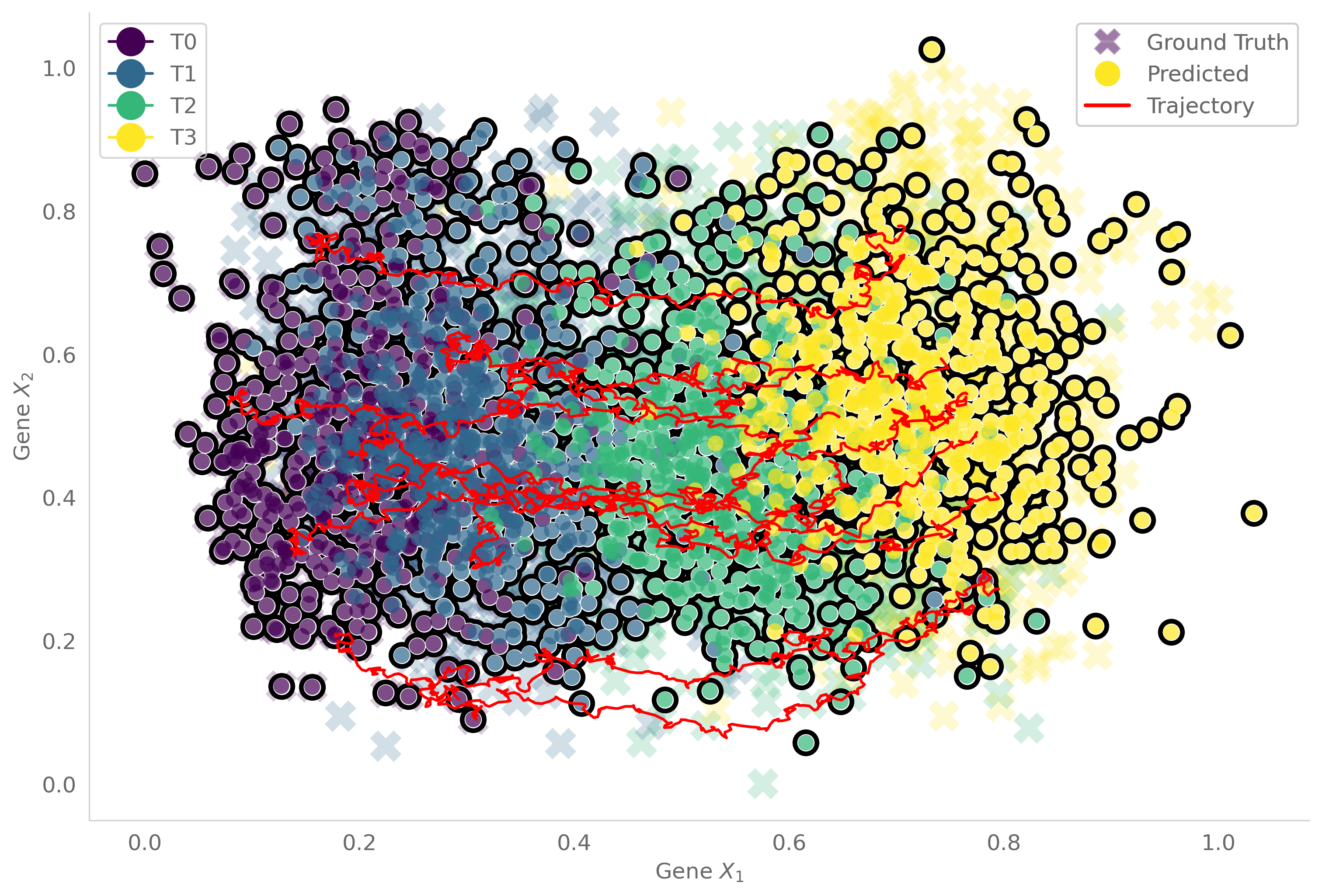
[15]:
# generate plot data
f_net.to('cuda')
generated, trajectories = generate_plot_data(
f_net, df, n_points=400, n_trajectories=50, n_bins=100,
sample_with_replacement=True, use_cuda=use_cuda, samples_key='samples',
logger=logger
)
tensor([0., 1., 2., 3.], device='cuda:0')
<class 'torch.Tensor'>
tensor([0.0000, 0.0303, 0.0606, 0.0909, 0.1212, 0.1515, 0.1818, 0.2121, 0.2424,
0.2727, 0.3030, 0.3333, 0.3636, 0.3939, 0.4242, 0.4545, 0.4848, 0.5152,
0.5455, 0.5758, 0.6061, 0.6364, 0.6667, 0.6970, 0.7273, 0.7576, 0.7879,
0.8182, 0.8485, 0.8788, 0.9091, 0.9394, 0.9697, 1.0000, 1.0303, 1.0606,
1.0909, 1.1212, 1.1515, 1.1818, 1.2121, 1.2424, 1.2727, 1.3030, 1.3333,
1.3636, 1.3939, 1.4242, 1.4545, 1.4848, 1.5152, 1.5455, 1.5758, 1.6061,
1.6364, 1.6667, 1.6970, 1.7273, 1.7576, 1.7879, 1.8182, 1.8485, 1.8788,
1.9091, 1.9394, 1.9697, 2.0000, 2.0303, 2.0606, 2.0909, 2.1212, 2.1515,
2.1818, 2.2121, 2.2424, 2.2727, 2.3030, 2.3333, 2.3636, 2.3939, 2.4242,
2.4545, 2.4848, 2.5152, 2.5455, 2.5758, 2.6061, 2.6364, 2.6667, 2.6970,
2.7273, 2.7576, 2.7879, 2.8182, 2.8485, 2.8788, 2.9091, 2.9394, 2.9697,
3.0000], device='cuda:0')
<class 'torch.Tensor'>
[17]:
plot_comparision(
df, generated, trajectories,
palette = 'viridis', df_time_key='samples',
save=True, path=exp_dir, file='comparision.png',
x='x1', y='x2', is_3d=False
)
[17]:
Pretrain score
[18]:
import pandas as pd
import anndata as ad
f_net.load_state_dict(torch.load(os.path.join(exp_dir+'/best_model'),map_location=torch.device('cpu')))
f_net.to(device)
print("DataFrame shape:", df.shape)
print("DataFrame columns:", df.columns)
n=dim
samples = df['samples'].values
column_names = [f'x{i}' for i in range(1, n + 1)]
obsm_data = df[column_names].values
print("obsm_data shape:", obsm_data.shape)
adata = ad.AnnData(obs=pd.DataFrame(index=samples))
adata.obsm['X_pca'] = obsm_data
adata_loaded = adata
print(adata_loaded)
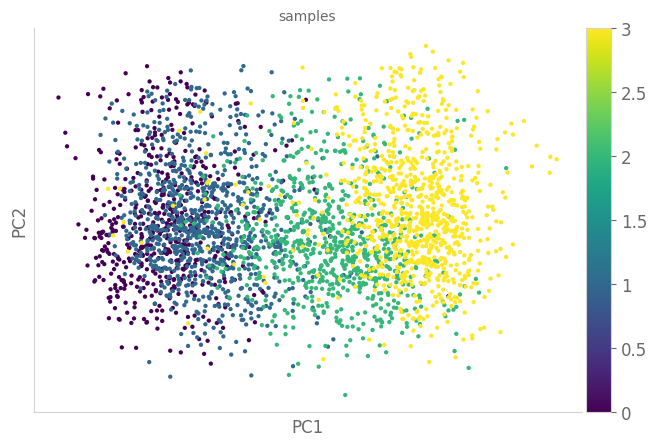
import scanpy as sc
adata.obs['samples']=df['samples'].values
sc.pl.scatter(adata, basis="pca", color="samples")
n_times = len(adata.obs["samples"].unique())
print(n_times)
X = [
adata.obsm["X_pca"][adata.obs["samples"] == t]
for t in range(n_times)
]
DataFrame shape: (3133, 11)
DataFrame columns: Index(['samples', 'x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x9', 'x10'], dtype='object')
obsm_data shape: (3133, 10)
AnnData object with n_obs × n_vars = 3133 × 0
obsm: 'X_pca'
/lustre/home/2301110060/software/miniconda3/envs/DeepRUOT/lib/python3.10/site-packages/anndata/_core/aligned_df.py:68: ImplicitModificationWarning: Transforming to str index.
warnings.warn("Transforming to str index.", ImplicitModificationWarning)
/lustre/home/2301110060/software/miniconda3/envs/DeepRUOT/lib/python3.10/site-packages/anndata/_core/anndata.py:1756: UserWarning: Observation names are not unique. To make them unique, call `.obs_names_make_unique`.
utils.warn_names_duplicates("obs")
4
[25]:
from DeepRUOT.utils import OTPlanSampler, ConditionalFlowMatcher, ExactOptimalTransportConditionalFlowMatcher, TargetConditionalFlowMatcher,SchrodingerBridgeConditionalFlowMatcher, VariancePreservingConditionalFlowMatcher,generate_state_trajectory
from DeepRUOT.models import scoreNet2
batch_size = df[df['samples']==0].x1.shape[0]
sigma = 0.05
time = torch.Tensor(groups)
SF2M = SchrodingerBridgeConditionalFlowMatcher(sigma=sigma)
sf2m_score_model=scoreNet2(in_out_dim=dim, hidden_dim=128, activation='leakyrelu').float().to(device)
sf2m_optimizer = torch.optim.Adam(
list(sf2m_score_model.parameters()), 1e-4
)
trajectory = generate_state_trajectory(X, n_times,batch_size, f_net, time, device)
[26]:
from DeepRUOT.utils import get_batch
max_norm_ut = torch.tensor(0.0)
lambda_penalty=0
for i in tqdm(range(3001)):
sf2m_optimizer.zero_grad()
t, xt, ut,eps = get_batch(SF2M, X, trajectory,batch_size, n_times, return_noise=True)
t=torch.unsqueeze(t,1)
lambda_t = SF2M.compute_lambda(t % 1)
value_st=sf2m_score_model(t, xt)
st = sf2m_score_model.compute_gradient(t, xt)
positive_st = torch.relu(value_st)
penalty = lambda_penalty * torch.max(positive_st)
# max_norm_ut = torch.maximum(torch.max(torch.sum(ut**2, dim=1)), max_norm_ut)
score_loss = torch.mean((lambda_t[:, None] * st + eps) ** 2)
if i % 100 == 0:
print(torch.max(positive_st))
print(f"{i}: {score_loss.item():0.2f}")
loss = score_loss+penalty
loss.backward()
sf2m_optimizer.step()
0%| | 2/3001 [00:00<05:05, 9.83it/s]
tensor(0.0455, device='cuda:0', grad_fn=<MaxBackward1>)
0: 1.01
3%|▎ | 102/3001 [00:10<04:52, 9.90it/s]
tensor(0.0121, device='cuda:0', grad_fn=<MaxBackward1>)
100: 0.99
7%|▋ | 202/3001 [00:20<04:43, 9.89it/s]
tensor(0.0203, device='cuda:0', grad_fn=<MaxBackward1>)
200: 1.00
10%|█ | 302/3001 [00:30<04:31, 9.94it/s]
tensor(0.0258, device='cuda:0', grad_fn=<MaxBackward1>)
300: 0.99
13%|█▎ | 402/3001 [00:40<04:21, 9.94it/s]
tensor(0.0272, device='cuda:0', grad_fn=<MaxBackward1>)
400: 0.99
17%|█▋ | 502/3001 [00:50<04:11, 9.94it/s]
tensor(0.0335, device='cuda:0', grad_fn=<MaxBackward1>)
500: 0.98
20%|██ | 602/3001 [01:00<04:01, 9.94it/s]
tensor(0.0322, device='cuda:0', grad_fn=<MaxBackward1>)
600: 0.98
23%|██▎ | 702/3001 [01:10<03:51, 9.93it/s]
tensor(0.0401, device='cuda:0', grad_fn=<MaxBackward1>)
700: 0.99
27%|██▋ | 802/3001 [01:20<03:41, 9.94it/s]
tensor(0.0458, device='cuda:0', grad_fn=<MaxBackward1>)
800: 1.00
30%|███ | 902/3001 [01:30<03:31, 9.95it/s]
tensor(0.0484, device='cuda:0', grad_fn=<MaxBackward1>)
900: 0.97
33%|███▎ | 1002/3001 [01:40<03:20, 9.95it/s]
tensor(0.0477, device='cuda:0', grad_fn=<MaxBackward1>)
1000: 0.99
37%|███▋ | 1102/3001 [01:50<03:11, 9.93it/s]
tensor(0.0474, device='cuda:0', grad_fn=<MaxBackward1>)
1100: 0.98
40%|████ | 1202/3001 [02:00<03:01, 9.93it/s]
tensor(0.0478, device='cuda:0', grad_fn=<MaxBackward1>)
1200: 1.00
43%|████▎ | 1302/3001 [02:10<02:51, 9.92it/s]
tensor(0.0546, device='cuda:0', grad_fn=<MaxBackward1>)
1300: 1.01
47%|████▋ | 1402/3001 [02:20<02:41, 9.89it/s]
tensor(0.0539, device='cuda:0', grad_fn=<MaxBackward1>)
1400: 0.99
50%|█████ | 1502/3001 [02:30<02:30, 9.95it/s]
tensor(0.0583, device='cuda:0', grad_fn=<MaxBackward1>)
1500: 0.98
53%|█████▎ | 1602/3001 [02:40<02:20, 9.95it/s]
tensor(0.0567, device='cuda:0', grad_fn=<MaxBackward1>)
1600: 0.99
57%|█████▋ | 1702/3001 [02:51<02:10, 9.95it/s]
tensor(0.0619, device='cuda:0', grad_fn=<MaxBackward1>)
1700: 0.99
60%|██████ | 1802/3001 [03:01<02:00, 9.95it/s]
tensor(0.0643, device='cuda:0', grad_fn=<MaxBackward1>)
1800: 0.98
63%|██████▎ | 1902/3001 [03:11<01:50, 9.93it/s]
tensor(0.0706, device='cuda:0', grad_fn=<MaxBackward1>)
1900: 0.98
67%|██████▋ | 2002/3001 [03:21<01:40, 9.95it/s]
tensor(0.0707, device='cuda:0', grad_fn=<MaxBackward1>)
2000: 0.98
70%|███████ | 2102/3001 [03:31<01:30, 9.94it/s]
tensor(0.0780, device='cuda:0', grad_fn=<MaxBackward1>)
2100: 1.00
73%|███████▎ | 2202/3001 [03:41<01:20, 9.94it/s]
tensor(0.0758, device='cuda:0', grad_fn=<MaxBackward1>)
2200: 0.99
77%|███████▋ | 2302/3001 [03:51<01:10, 9.94it/s]
tensor(0.0805, device='cuda:0', grad_fn=<MaxBackward1>)
2300: 1.01
80%|████████ | 2402/3001 [04:01<01:00, 9.92it/s]
tensor(0.0822, device='cuda:0', grad_fn=<MaxBackward1>)
2400: 1.00
83%|████████▎ | 2502/3001 [04:11<00:50, 9.91it/s]
tensor(0.0834, device='cuda:0', grad_fn=<MaxBackward1>)
2500: 0.98
87%|████████▋ | 2602/3001 [04:21<00:40, 9.91it/s]
tensor(0.0845, device='cuda:0', grad_fn=<MaxBackward1>)
2600: 0.99
90%|█████████ | 2702/3001 [04:31<00:30, 9.90it/s]
tensor(0.0882, device='cuda:0', grad_fn=<MaxBackward1>)
2700: 0.98
93%|█████████▎| 2802/3001 [04:41<00:20, 9.94it/s]
tensor(0.0902, device='cuda:0', grad_fn=<MaxBackward1>)
2800: 0.99
97%|█████████▋| 2902/3001 [04:51<00:09, 9.94it/s]
tensor(0.0921, device='cuda:0', grad_fn=<MaxBackward1>)
2900: 0.99
100%|██████████| 3001/3001 [05:01<00:00, 9.95it/s]
tensor(0.0913, device='cuda:0', grad_fn=<MaxBackward1>)
3000: 0.99
[27]:
torch.save(sf2m_score_model.state_dict(), os.path.join(exp_dir, 'score_model'))
[30]:
import numpy as np
import matplotlib.pyplot as plt
import torch
x_range = np.linspace(0, 1, 100)
y_range = np.linspace(0, 1, 100)
xv, yv = np.meshgrid(x_range, y_range)
grid_points = np.stack([xv, yv], axis=-1).reshape(-1, 2)
grid_points_tensor = torch.tensor(grid_points).float().to(device)
padding_dim=dim-2
padding_tensor = torch.zeros(10000, padding_dim).to(device)
expanded_tensor = torch.cat((grid_points_tensor, padding_tensor), dim=1)
t_value = 2.0
t_tensor = torch.tensor([t_value] * grid_points.shape[0]).unsqueeze(1).float().to(device)
print(t_tensor.shape)
expanded_tensor.requires_grad_(True)
log_density_values = sf2m_score_model(t_tensor, expanded_tensor)
density_values=torch.exp(log_density_values)
log_density_values.backward(torch.ones_like(log_density_values))
gradients = expanded_tensor.grad
print(gradients.shape)
gradients_np = gradients.cpu().detach().numpy().reshape(100, 100, dim)
step = 5
xv_quiver = xv[::step, ::step]
yv_quiver = yv[::step, ::step]
gradients_np_quiver = gradients_np[::step, ::step, :]
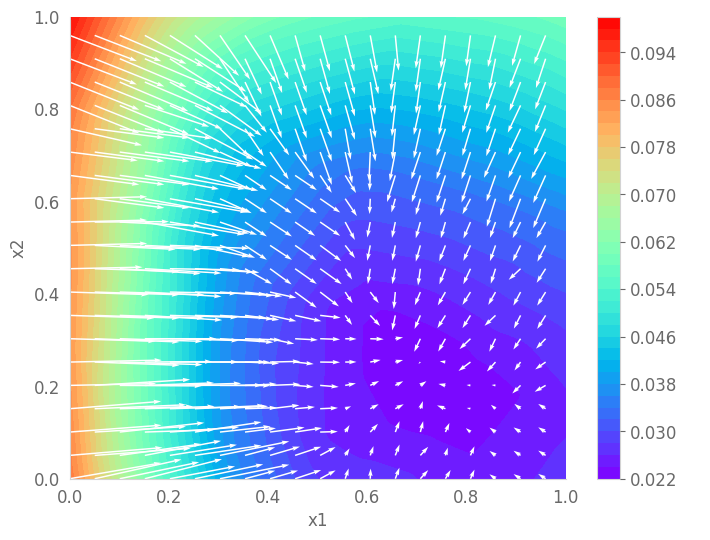
plt.figure(figsize=(8, 6))
plt.contourf(xv, yv, -log_density_values.cpu().detach().numpy().reshape(100, 100), levels=50, cmap='rainbow')
plt.colorbar(label=' ')
plt.quiver(xv_quiver, yv_quiver, gradients_np_quiver[:, :, 0], gradients_np_quiver[:, :, 1], color='white', scale=1)
plt.xlabel('x1')
plt.ylabel('x2')
#plt.savefig('score_t_0_gaussian.pdf')
plt.show()
torch.Size([10000, 1])
torch.Size([10000, 10])
Train
[31]:
sf2m_score_model.load_state_dict(torch.load(os.path.join(exp_dir, 'score_model'),map_location=torch.device('cpu')))
sf2m_score_model.to(device)
f_net.load_state_dict(torch.load(os.path.join(exp_dir+'/best_model'),map_location=torch.device('cpu')))
f_net.to(device)
for param in f_net.g_net.parameters():
param.requires_grad = True
[31]:
FNet(
(v_net): velocityNet(
(activation): LeakyReLU(negative_slope=0.01)
(net): ModuleList(
(0): Sequential(
(0): Linear(in_features=11, out_features=128, bias=True)
(1): LeakyReLU(negative_slope=0.01)
)
(1-2): 2 x Sequential(
(0): Linear(in_features=128, out_features=128, bias=True)
(1): LeakyReLU(negative_slope=0.01)
)
)
(out): Linear(in_features=128, out_features=10, bias=True)
)
(g_net): growthNet(
(activation): LeakyReLU(negative_slope=0.01)
(net): Sequential(
(0): Linear(in_features=11, out_features=128, bias=True)
(1): LeakyReLU(negative_slope=0.01)
(2): Linear(in_features=128, out_features=128, bias=True)
(3): LeakyReLU(negative_slope=0.01)
(4): Linear(in_features=128, out_features=128, bias=True)
(5): LeakyReLU(negative_slope=0.01)
(6): Linear(in_features=128, out_features=1, bias=True)
)
)
(s_net): scoreNet(
(activation): LeakyReLU(negative_slope=0.01)
(net): Sequential(
(0): Linear(in_features=11, out_features=128, bias=True)
(1): LeakyReLU(negative_slope=0.01)
(2): Linear(in_features=128, out_features=128, bias=True)
(3): LeakyReLU(negative_slope=0.01)
(4): Linear(in_features=128, out_features=128, bias=True)
(5): LeakyReLU(negative_slope=0.01)
(6): Linear(in_features=128, out_features=1, bias=True)
)
)
(d_net): indediffusionNet(
(activation): LeakyReLU(negative_slope=0.01)
(net): Sequential(
(0): Linear(in_features=1, out_features=128, bias=True)
(1): LeakyReLU(negative_slope=0.01)
(2): Linear(in_features=128, out_features=128, bias=True)
(3): LeakyReLU(negative_slope=0.01)
(4): Linear(in_features=128, out_features=128, bias=True)
(5): LeakyReLU(negative_slope=0.01)
(6): Linear(in_features=128, out_features=1, bias=True)
)
)
)
[13]:
import numpy as np
from DeepRUOT.utils import density1
import matplotlib.pyplot as plt
import torch
datatime0=torch.zeros(df[df['samples']==0].x1.shape[0],dim)
datatime0[:, 0] = torch.tensor(df[df['samples'] == 0].x1.values, dtype=torch.float32)
datatime0[:, 1] = torch.tensor(df[df['samples'] == 0].x2.values, dtype=torch.float32)
device='cpu'
x_range = np.linspace(0, 1, 100)
y_range = np.linspace(0, 1, 100)
xv, yv = np.meshgrid(x_range, y_range)
num_grid_points = xv.size # Total number of grid points (10000)
# Initialize a grid with 10 dimensions: first two vary, others are zero
grid_points = np.zeros((num_grid_points, dim), dtype=np.float32)
grid_points[:, 0] = xv.flatten()
grid_points[:, 1] = yv.flatten()
# Convert grid points to a PyTorch tensor and move to the appropriate device
grid_points_tensor = torch.tensor(grid_points).float().to(device)
grid_points_tensor = torch.tensor(grid_points).float().to(device)
with torch.no_grad():
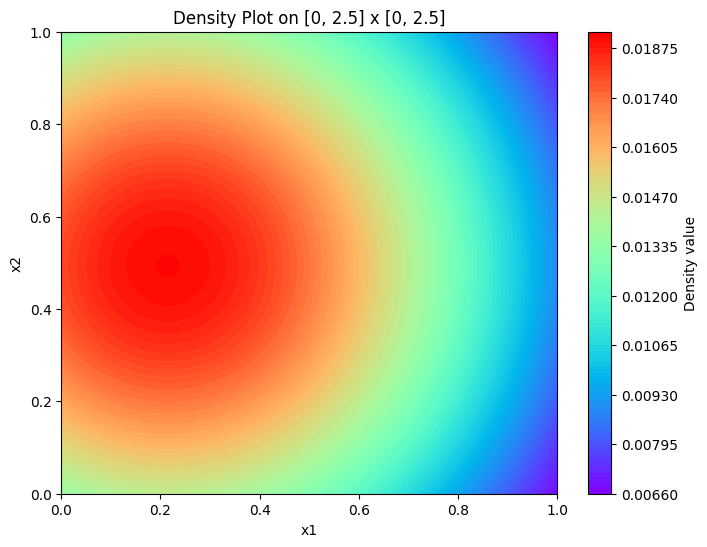
function_values = density1(grid_points_tensor,datatime0,device).cpu().detach().numpy().reshape(100, 100)
#function_values=np.log(function_values)
plt.figure(figsize=(8, 6))
plt.contourf(xv, yv, function_values, levels=100, cmap='rainbow')
plt.colorbar(label='Density value')
plt.xlabel('x1')
plt.ylabel('x2')
plt.title('Density Plot on [0, 2.5] x [0, 2.5]')
plt.show()
[14]:
from DeepRUOT.train import train_all
device='cpu'
optimizer = torch.optim.SGD(list(f_net.parameters())+list(sf2m_score_model.parameters()),1e-5)
[ ]:
#new
if n_local_epochs > 0:
logger.info(f'Beginning Training')
for epoch in tqdm(range(1), desc='Training Epoch'):
l_loss, b_loss, g_loss = train_all(
f_net, df, groups, optimizer,10,
criterion = criterion, use_cuda = use_cuda,
local_loss=True, global_loss=False, apply_losses_in_time=apply_losses_in_time,
hold_one_out=hold_one_out, hold_out=hold_out, sf2m_score_model=sf2m_score_model,
hinge_value=hinge_value,datatime0=datatime0,device=device, lambda_initial=0.1,
use_pinn=True, use_penalty=True,use_density_loss=False,lambda_density=10,
top_k = top_k, sample_size = sample_size,relative_mass=relative_mass,initial_size=initial_size,
sample_with_replacement = sample_with_replacement, logger=logger, sigmaa=sigma,lambda_pinn=1,
)
for k, v in l_loss.items():
local_losses[k].extend(v)
batch_losses.extend(b_loss)
globe_losses.extend(g_loss)
[17]:
torch.save(sf2m_score_model.state_dict(), os.path.join(exp_dir, 'score_model_result'))
torch.save(f_net.state_dict(), os.path.join(exp_dir, 'model_result'))
[32]:
data=torch.tensor(df[df['samples']==0].values,dtype=torch.float32).requires_grad_()
data_t0 = data[:, 1:dim+1].to(device).requires_grad_()
print(data_t0.shape)
x0=data_t0.to(device)
torch.Size([577, 10])
[37]:
import torchsde
class SDE(torch.nn.Module):
noise_type = "diagonal"
sde_type = "ito"
def __init__(self, ode_drift, score, input_size=(3, 32, 32), sigma=1.0):
super().__init__()
self.drift = ode_drift
self.score = score
self.input_size = input_size
self.sigma = sigma
# Drift
def f(self, t, y):
drift=self.drift(t,y)
num = y.shape[0]
t = t.expand(num, 1)
return drift+self.score.compute_gradient(t,y)
# Diffusion
def g(self, t, y):
return torch.ones_like(y)*sigma
sde = SDE(f_net.v_net, sf2m_score_model, input_size=(dim,), sigma=sigma)
sde_traj = torchsde.sdeint(
sde,
x0.to(device),
dt=0.01,
ts=torch.linspace(0, n_times - 1, 400, device=device),
).cpu()
[38]:
# define sample_number
sample_number = 10
sample_indices = random.sample(range(sde_traj.size(1)), sample_number)
sampled_sde_trajec = sde_traj[:, sample_indices, :]
sampled_sde_trajec.shape
sampled_sde_trajec = sampled_sde_trajec.tolist()
sampled_sde_trajec = np.array(sampled_sde_trajec, dtype=object)
np.save(exp_dir+'/sde_trajec_our_post_plot.npy', sampled_sde_trajec)
[40]:
ts_points=time.to(device)
ts_points
sde_point = torchsde.sdeint(
sde,
x0.to(device),
dt=0.01,
ts=ts_points,
).cpu()
[41]:
sde_point_np = sde_point.detach().numpy()
sde_point_list = sde_point_np.tolist()
sde_point_array = np.array(sde_point_list, dtype=object)
np.save(exp_dir+'/sde_point_our_post.npy', sde_point_array)
[42]:
sde_point_our_post=np.load(exp_dir+'/sde_point_our_post.npy',allow_pickle=True)
[27]:
sde_point_our_post=sde_point_our_post[:,100:300,:]
sde_point_our_post.shape
[27]:
(4, 200, 10)
[43]:
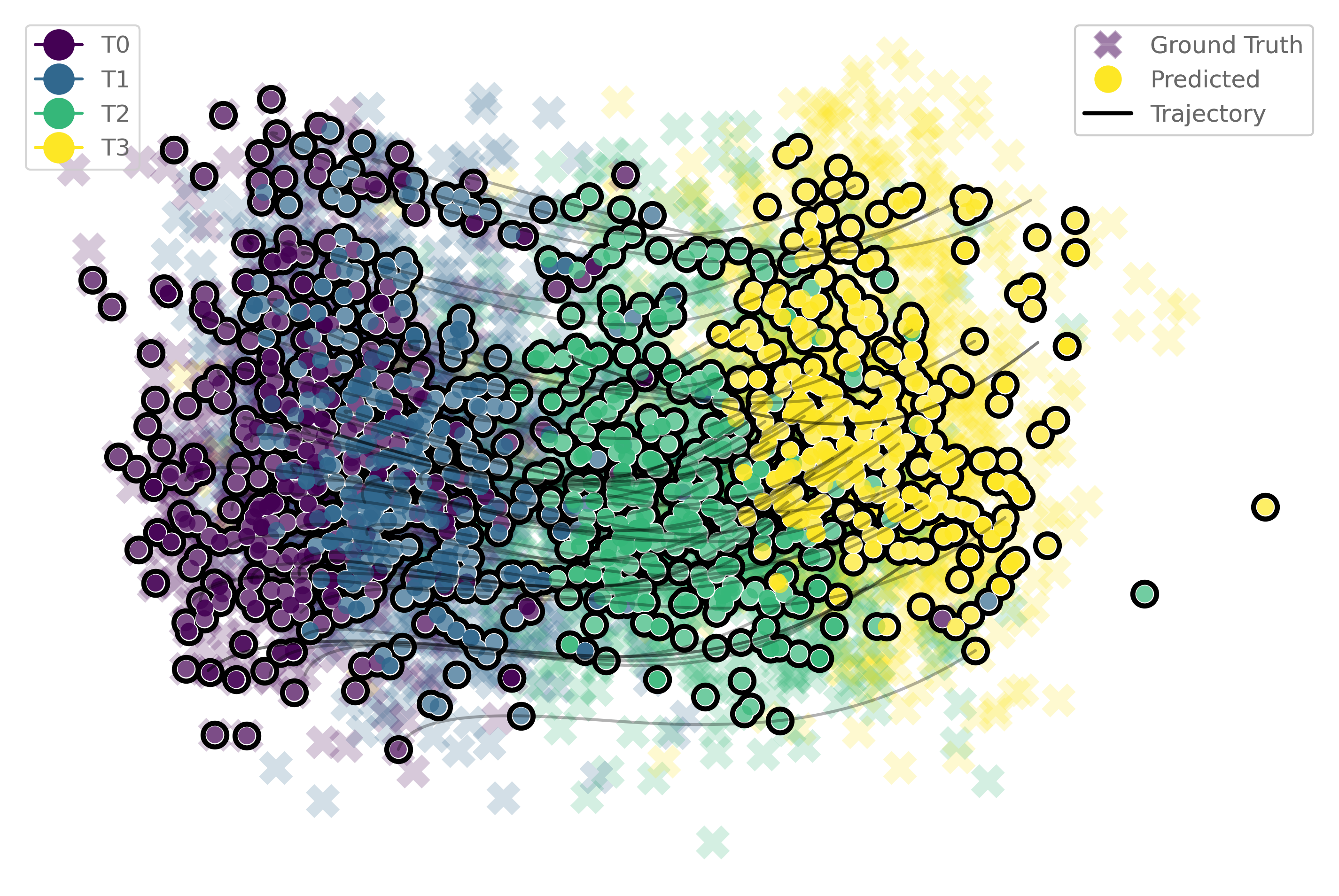
from DeepRUOT.plots import new_plot_comparisions2
[44]:
sde_trajec_our_post_plot=np.load(exp_dir+'/sde_trajec_our_post_plot.npy',allow_pickle=True)
new_plot_comparisions2(
df, sde_point_our_post, sde_trajec_our_post_plot,
palette = 'viridis', df_time_key='samples',
save=True, path=exp_dir, file='sde_trajec_our_post_plot.pdf',
x='x1', y='x2', z='x3',is_3d=False
)
[44]: