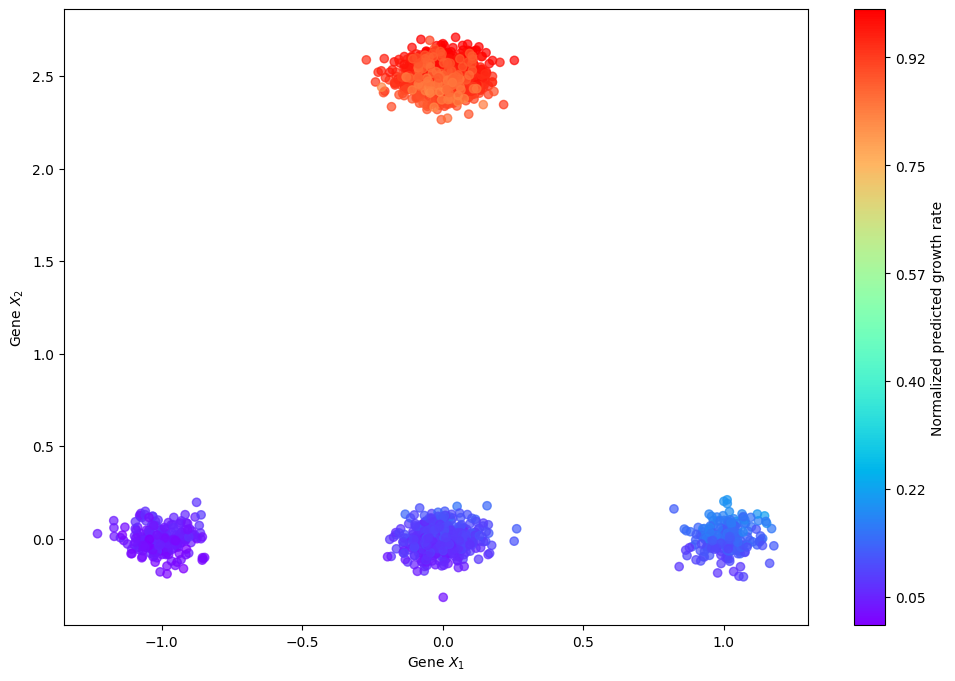
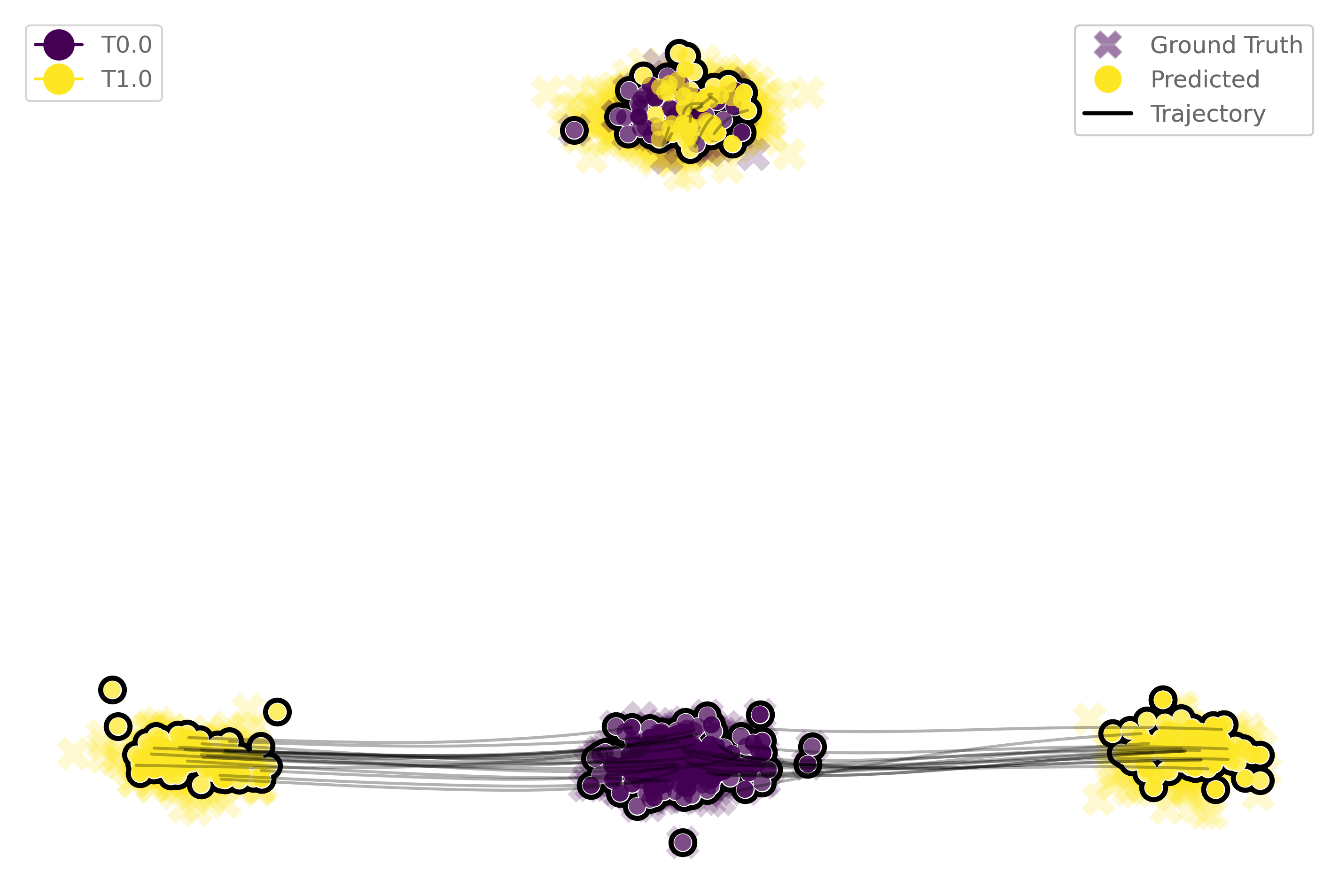
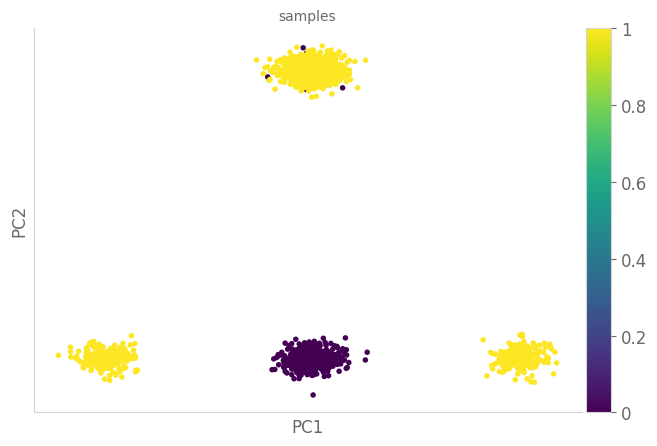
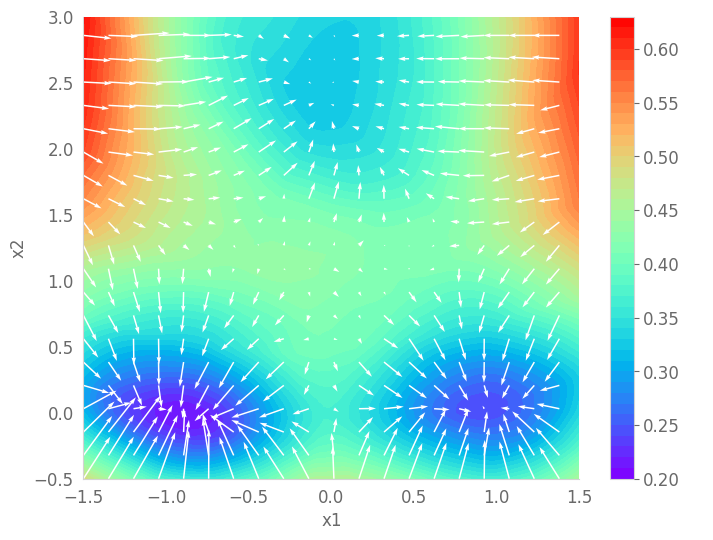
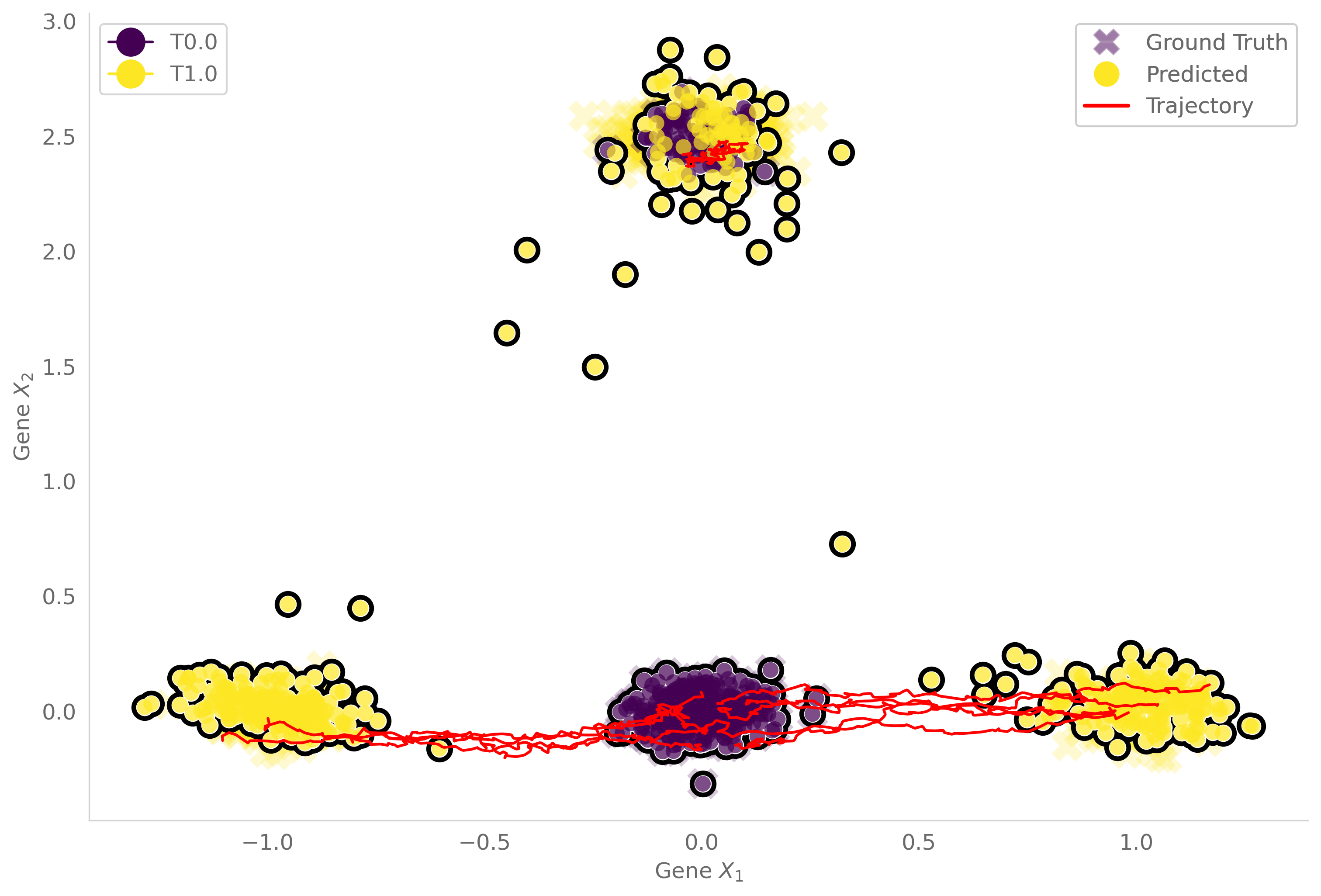
Otloss
tensor(0.7331, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2986, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.7331304550170898. Model saved.
Otloss
tensor(0.7212, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2921, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.7211790084838867. Model saved.
Otloss
tensor(0.7078, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2838, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.7078102827072144. Model saved.
Otloss
tensor(0.6936, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2730, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.6936277151107788. Model saved.
Otloss
tensor(0.6787, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2611, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.6786981821060181. Model saved.
Otloss
tensor(0.6630, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2519, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.663044810295105. Model saved.
Otloss
tensor(0.6467, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2435, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.6467463970184326. Model saved.
Otloss
tensor(0.6302, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2381, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.6301634311676025. Model saved.
Otloss
tensor(0.6134, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2352, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.6134482622146606. Model saved.
Otloss
tensor(0.5964, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2298, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.5964141488075256. Model saved.
Otloss
tensor(0.5792, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2281, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.5792098045349121. Model saved.
Otloss
tensor(0.5620, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2256, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.5620136260986328. Model saved.
Otloss
tensor(0.5450, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2260, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.5449652075767517. Model saved.
Otloss
tensor(0.5282, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2270, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.5282033085823059. Model saved.
Otloss
tensor(0.5118, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2274, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.5117811560630798. Model saved.
Otloss
tensor(0.4957, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2255, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.4956590533256531. Model saved.
Otloss
tensor(0.4799, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2265, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.4798792600631714. Model saved.
Otloss
tensor(0.4645, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2286, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.4645465314388275. Model saved.
Otloss
tensor(0.4498, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2295, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.4497615098953247. Model saved.
Otloss
tensor(0.4356, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2285, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.43557965755462646. Model saved.
Otloss
tensor(0.4221, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2277, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.42214110493659973. Model saved.
Otloss
tensor(0.4094, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2238, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.4094284176826477. Model saved.
Otloss
tensor(0.3975, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2263, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.3974587023258209. Model saved.
Otloss
tensor(0.3863, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2253, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.3862609267234802. Model saved.
Otloss
tensor(0.3757, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2288, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.37572383880615234. Model saved.
Otloss
tensor(0.3658, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2280, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.3658371567726135. Model saved.
Otloss
tensor(0.3572, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2257, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.35719695687294006. Model saved.
Otloss
tensor(0.3622, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2242, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.3676, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2235, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.3731, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2253, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.3786, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2255, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.3839, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2224, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.3890, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2197, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.3937, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2181, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.3979, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2125, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4015, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2064, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4047, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2024, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4073, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.2016, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4093, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1956, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4109, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1916, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4122, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1891, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4131, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1874, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4137, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1861, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4140, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1868, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4140, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1877, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4137, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1861, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4134, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1831, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4132, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1820, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4129, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1803, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4123, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1768, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4115, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1761, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4103, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1782, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4089, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1776, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4072, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1766, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4049, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1751, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.4019, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1732, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.3982, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1729, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.3938, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1732, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.3886, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1723, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.3826, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1717, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.3759, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1723, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.3685, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1752, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.3604, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1748, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.3512, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1741, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.3512299358844757. Model saved.
Otloss
tensor(0.3409, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1714, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.34086132049560547. Model saved.
Otloss
tensor(0.3291, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1641, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.32905030250549316. Model saved.
Otloss
tensor(0.3158, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1637, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.31582117080688477. Model saved.
Otloss
tensor(0.3011, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1705, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.3011268973350525. Model saved.
Otloss
tensor(0.2863, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1781, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.28631168603897095. Model saved.
Otloss
tensor(0.2736, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1848, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.2735878825187683. Model saved.
Otloss
tensor(0.2627, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1916, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.2627209722995758. Model saved.
Otloss
tensor(0.2516, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1806, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.2515758275985718. Model saved.
Otloss
tensor(0.2402, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1507, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.2402287870645523. Model saved.
Otloss
tensor(0.2287, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.1192, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.22868338227272034. Model saved.
Otloss
tensor(0.2182, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0884, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.21823400259017944. Model saved.
Otloss
tensor(0.2099, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0743, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.20994432270526886. Model saved.
Otloss
tensor(0.2043, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0726, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.20429208874702454. Model saved.
Otloss
tensor(0.1990, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0686, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.19898957014083862. Model saved.
Otloss
tensor(0.1931, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0649, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.19308674335479736. Model saved.
Otloss
tensor(0.1871, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0591, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.1870669722557068. Model saved.
Otloss
tensor(0.1818, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0589, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.18183431029319763. Model saved.
Otloss
tensor(0.1787, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0565, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.17872890830039978. Model saved.
Otloss
tensor(0.1782, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0557, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.17815589904785156. Model saved.
Otloss
tensor(0.1789, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0578, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1793, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0575, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1781, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0532, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.178134024143219. Model saved.
Otloss
tensor(0.1755, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0530, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.1754778027534485. Model saved.
Otloss
tensor(0.1729, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0527, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.17287935316562653. Model saved.
Otloss
tensor(0.1711, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0505, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.17110714316368103. Model saved.
Otloss
tensor(0.1703, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0500, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.170296311378479. Model saved.
Otloss
tensor(0.1704, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0518, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1709, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0515, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1716, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0505, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1723, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0495, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1730, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0493, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1735, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0497, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1733, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0517, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1724, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0549, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1711, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0557, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1702, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0524, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.17022699117660522. Model saved.
Otloss
tensor(0.1704, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0536, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1714, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0545, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1725, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0535, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1732, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0540, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1731, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0548, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1725, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0561, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1718, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0544, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1710, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0542, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1706, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0538, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1706, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0525, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1702, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0535, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.1701781451702118. Model saved.
Otloss
tensor(0.1691, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0540, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.16906479001045227. Model saved.
Otloss
tensor(0.1677, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0532, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.16768932342529297. Model saved.
Otloss
tensor(0.1667, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0542, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.1667085886001587. Model saved.
Otloss
tensor(0.1662, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0552, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.16616453230381012. Model saved.
Otloss
tensor(0.1656, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0549, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.1656438410282135. Model saved.
Otloss
tensor(0.1649, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0552, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.164910688996315. Model saved.
Otloss
tensor(0.1638, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0562, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.16382265090942383. Model saved.
Otloss
tensor(0.1627, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0558, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.16272491216659546. Model saved.
Otloss
tensor(0.1621, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0544, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.16214200854301453. Model saved.
Otloss
tensor(0.1617, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0523, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.16168060898780823. Model saved.
Otloss
tensor(0.1603, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0509, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.16030660271644592. Model saved.
Otloss
tensor(0.1585, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0514, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.15852797031402588. Model saved.
Otloss
tensor(0.1575, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0526, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.15752866864204407. Model saved.
Otloss
tensor(0.1571, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0529, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.15708552300930023. Model saved.
Otloss
tensor(0.1563, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0540, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.15627995133399963. Model saved.
Otloss
tensor(0.1550, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0557, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.15501251816749573. Model saved.
Otloss
tensor(0.1542, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0549, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.15422654151916504. Model saved.
Otloss
tensor(0.1537, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0550, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.15365956723690033. Model saved.
Otloss
tensor(0.1528, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0551, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.15275242924690247. Model saved.
Otloss
tensor(0.1514, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0559, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.15143916010856628. Model saved.
Otloss
tensor(0.1507, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0552, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.15069769322872162. Model saved.
Otloss
tensor(0.1498, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0554, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.14983034133911133. Model saved.
Otloss
tensor(0.1481, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0543, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.14812082052230835. Model saved.
Otloss
tensor(0.1471, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0541, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.14707276225090027. Model saved.
Otloss
tensor(0.1453, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0551, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.14530467987060547. Model saved.
Otloss
tensor(0.1433, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0559, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.14328408241271973. Model saved.
Otloss
tensor(0.1417, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0550, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.14167150855064392. Model saved.
Otloss
tensor(0.1394, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0554, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.1393733024597168. Model saved.
Otloss
tensor(0.1381, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0553, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.13814082741737366. Model saved.
Otloss
tensor(0.1357, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0536, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.13566741347312927. Model saved.
Otloss
tensor(0.1357, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0522, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1295, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0540, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.12948617339134216. Model saved.
Otloss
tensor(0.1372, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0529, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1225, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0564, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.12251230329275131. Model saved.
Otloss
tensor(0.1289, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0522, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1270, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0511, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1174, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0522, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.11744575202465057. Model saved.
Otloss
tensor(0.1230, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0489, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1240, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0491, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1153, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0487, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.11532987654209137. Model saved.
Otloss
tensor(0.1208, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0471, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1210, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0468, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1137, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0472, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.11372380703687668. Model saved.
Otloss
tensor(0.1216, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0465, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1134, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0479, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.11344195157289505. Model saved.
Otloss
tensor(0.1112, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0486, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.11122848093509674. Model saved.
Otloss
tensor(0.1188, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0465, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1083, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0497, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.108262799680233. Model saved.
Otloss
tensor(0.1167, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0439, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1070, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0466, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.10695388913154602. Model saved.
Otloss
tensor(0.1052, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0495, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.10524171590805054. Model saved.
Otloss
tensor(0.1239, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0405, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1031, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0459, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.1030769944190979. Model saved.
Otloss
tensor(0.1026, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0518, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.10256614536046982. Model saved.
Otloss
tensor(0.1157, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0406, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1115, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0404, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0981, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0512, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.09812656044960022. Model saved.
Otloss
tensor(0.0992, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0499, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0977, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0419, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.09769077599048615. Model saved.
Otloss
tensor(0.1079, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0374, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1049, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0394, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0963, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0462, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.0963270366191864. Model saved.
Otloss
tensor(0.0937, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0480, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.0936737209558487. Model saved.
Otloss
tensor(0.0974, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0422, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1064, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0377, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1086, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0362, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1010, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0391, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0934, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0461, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.09341716021299362. Model saved.
Otloss
tensor(0.0929, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0464, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.09289030730724335. Model saved.
Otloss
tensor(0.1020, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0381, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1063, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0368, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0997, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0380, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0977, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0431, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0948, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0394, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0970, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0393, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0982, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0444, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0939, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0349, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1024, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0355, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0933, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0353, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0963, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0395, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0932, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0368, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0976, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0342, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0943, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0333, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0928, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0342, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.09276648610830307. Model saved.
Otloss
tensor(0.0930, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0345, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0921, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0325, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.0921473428606987. Model saved.
Otloss
tensor(0.0943, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0307, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0925, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0313, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0911, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0315, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.09113812446594238. Model saved.
Otloss
tensor(0.0914, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0317, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0908, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0306, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.09075680375099182. Model saved.
Otloss
tensor(0.0929, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0310, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0921, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0297, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0898, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0309, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.08983145654201508. Model saved.
Otloss
tensor(0.0894, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0298, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.08939330279827118. Model saved.
Otloss
tensor(0.0903, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0297, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0926, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0282, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0915, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0269, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0900, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0274, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0900, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0305, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0901, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0303, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0902, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0303, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0904, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0301, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0903, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0291, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0893, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0287, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.08929537236690521. Model saved.
Otloss
tensor(0.0880, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0278, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.0879611074924469. Model saved.
Otloss
tensor(0.0870, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0280, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.08699000626802444. Model saved.
Otloss
tensor(0.0882, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0273, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0924, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0261, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0968, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0252, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0980, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0250, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0911, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0252, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0891, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0291, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0895, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0286, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0860, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0295, device='cuda:0', grad_fn=<PowBackward0>)
New minimum otloss found: 0.08603987097740173. Model saved.
Otloss
tensor(0.0872, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0300, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0914, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0295, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0977, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0310, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1010, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0291, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0972, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0255, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0878, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0231, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0918, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0241, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0902, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0217, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1035, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0262, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0886, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0318, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1086, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0334, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1016, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0226, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1153, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0343, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1147, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0302, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0995, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0266, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1181, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0550, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1308, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0457, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1030, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0284, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0970, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0411, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1343, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0651, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1187, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0464, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.0969, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0340, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1152, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0467, device='cuda:0', grad_fn=<PowBackward0>)
Otloss
tensor(0.1214, device='cuda:0', grad_fn=<SumBackward0>)
mass loss
tensor(0.0581, device='cuda:0', grad_fn=<PowBackward0>)